

Turn detection is essentially about detecting very precisely when the human speaker stopped speaking and triggering the bot’s reaction. For example the speaker is speaking and the bot listens carefully and then the speaker pauses to think using words like maybe or but let me think. This is a crucial moment of turn taking, the voice agent has to decide whether to wait for the human to resume speaking or to interrupt and provide its response in context.
So as it may happen that the human resumes speaking after this and the bot can go back to the listening mode and get the full context of the conversation as opposed to interjecting and destroying the naturalness or fullness of the conversation. The usual way in which this takes place is through a voice activity detector. So as soon as the user stops speaking, within millisecond the voice detector will signal that the speaker has stopped and the bot can take over. Typically the voice detector is controlled by a threshold. It means that for how long it waits before deciding the human has finished speaking
The issue is especially in instances where the user is just thinking or they’re in the middle of thought and will resume conversation but the bot doesn’t know that and it might interject or interrupt very quickly and destroy the conversation. So voice activity detection is the naive implementation in which you would implement turn detection.
The sophisticated system works by understanding the speaker’s intent by analyzing what the user has been speaking, the words that the user has been using and the audio intonation and prosody of the user. And by taking that into account, predict whether the speaker has actually finished what they wanted to say.
Architectural Role of Turn Detection in Speech Processing Pipeline
The voice agent pipeline begins with audio input, where the first stage is voice isolation or background noise removal. Immediately after this stage, the turn detection model comes in very early in the pipeline, therefore it has to be very fast.
It takes in these 100 millisecond audio frames, calculates the probability of end of turn for each frame and if the end of turn is not detected, the system just continues accumulating those frames. Once end of turn is predicted then all the accumulated frames are sent to the voice AI or or alternatively to a speech-to-text system, which then analyzes and transcribes the accumulated frame.
This component operates very close to the audio input stage and any delay or misunderstanding at this stage impacts the whole process.
Why is Turn Detection hard?
Turn detection is a crucial operation as we discussed. But what makes it really hard is that you want it to be really low latency.
Turn changes happen very frequently in a conversation and you don’t want the turn detection to take up a lot of time to destroy the natural flow of the conversation. Because at the back of the system, typically there’s a speech-to-text detection, there’s a text-to-speech module, there is a LLM working to convert what the user said into useful actions and you don’t want the turn detection to take up a lot of time. So, you want low latency and you want it to be fluid. To achieve that, we must examine the spectrum of turn detection with the efficiency of turn detection.
So if the detection is too early, the agent would interrupt the speaker before they have finished and that would destroy the conversation. On the other hand, if the voice activity detector is too late and spends a lot of time to ensure that the speaker has definitely finished speaking, it would make an agent sluggish. And as a result, humans would have to wait a long time before the agent responds and that will make the human impatient.
So what we need is a sweet spot of fluid interaction. Just in time; maybe slightly delayed to ensure that the user has indeed finished and then immediately comes in with the bird’s response.
So this trade-off spectrum of finding the sweet spot where a bot may come in time and won’t interject is what makes this problem complicated and the very interesting ML tradeoff.
So let’s look at the problem in terms of an algorithmic approach. How do you implement turn detection? So inside the system, human speech is not processed as one big file, rather in the form of chunks like 0–100ms, 100–200ms, 200–300ms, and so on. And what the system wants to know is when the user has indeed stopped speaking. That moment is the end-of-turn boundary.
So this is a sequence labeling problem. Every chunk gets assigned a probability that the user is speaking. When the speaker is actively talking the chunk is assigned high probability and when speaker lowers voice, or pauses, the model’s confidence gradually decreases and so the probability assigned. Finally, when the user fully stops speaking and silence is detected, the probability drops close to zero.
So the boundary limit comes when the system decides that the probability of speech is low enough that you can call it the end of the turn and at that point an AI voice assistant can take over.
So what’s crucial is the threshold where you determine based on your detector that the speech has stopped and chunk probability is least. This is the classic machine learning problem trade-off as there isn’t a fixed value where you definitely know for sure that the speaker is done speaking and you have to play around with the probabilities and thresholds to find a working practical value where you can safely assume that the speech is stopped.
In which Forms System can Identify Turn Detection
So we discussed VAD duration based detection earlier. In duration based detection, set up a time duration for which the system will wait and if no speech comes up in that time then it means speech is ended and AI voice assistants can take over.
But this has the usual problem that the user may pause for some time, think and then start speaking again and the system might get a false positive okay and take over. That was the very first VAD implementation which AI call centers generally start with but then they have to move on to more sophisticated machine learning based approaches for turn detection.
Let’s now discuss how the system can detect turns. There are three possible ways:
- Text
- Audio
- Hybrid
Audio-based Turn Detection
So speech carries a lot of characteristics which can help you to detect the end of speech. These characteristics include acoustic, prosodic features and temporal features that a machine learning model can use to detect if the user actually intended to finish or or if they are still thinking and and they’ll continue.
So you can implement this sort of semantic turn detection by building an audio-based classifier sequence labeler. It takes in a sequence of chunks and uses a bunch of audio features like pitch or energy pauses, speaking rate intonation and so on to assign probability to each chunk. And on the basis of probability, the system decides the continuation of speech or its end.
Text-based Turn Detection
In, text-based turn, the system transcribes audio to text and then you look at the text for detecting the turn. For example if the last token was maybe or but then it means that the user is most probably speaking and if there are discourse markers like full stop and words like that’s all it means speech is either over or about to conclude.
Hybrid Turn Detection
The more complex models are hybrid turn detector models which use both audio and text in a synchronized way to predict if the turn has ended or not.
Turn Detection Evaluation Metrics
Let’s learn how to quantify whether a turn detector is good or bad?
Mean Shift Time
The mean shift time is the primary metric which is the duration between the silence ends and the detector detects that speech has ended. So depending on the mean shift time, you can determine how quick or how sluggish it is. You get a mean shift time, measure how long the detector takes to react in many cases and then calculate the average reaction time. Generally want a very small short mean shift time
False Positive Responses
Accuracy measures how many times false positive responses a system generates. False positive is a classic sequence labeling problem. So both accuracy tradeoff and latency trade-offs are bound to happen.
Balancing Mean Shift Time and False Positive Rate
As discussed earlier, turn detectors assign probability to audio chunks. The high probability means the speaker is actively speaking while lower ones highlight that the speech is either ending or about to end.
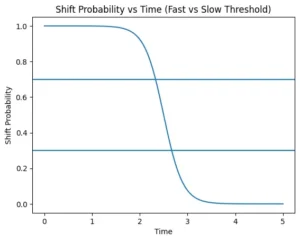
For voice detection, engineers have to decide the threshold probability at which system decides that speech is ending. If your system has a low threshold on the probability output then the system takes a fast shift and if it has a high threshold, it waits for the probability output to come to a high level and consequently shifts slowly
Slow shift is more cautious so you get better accuracy but you lose latency and can feel less responsive.
The following diagram shows the trade-off between the false positive rate and the mean shift time. As you allow longer shift time the false positive rate decreases significantly. So the only problem is if you want to be very quick there will be many more false positives.
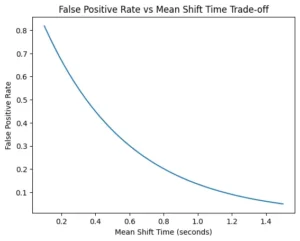
An efficient turn detector navigates these trade-offs between the mean shift time and the false positives.
FAQs about Turn Detection
What is turn detection in conversational AI?
Turn taking is essentially about detecting very precisely when the human speaker stopped speaking and triggering the bot’s reaction without interrupting or delaying the conversation.
Why is turn detection difficult in real-time voice systems?
Turn changes happen very frequently in a conversation and you don’t want the turn detection to take up a lot of time to destroy the natural flow of the conversation. This component operates very close to the audio input stage and any delay or misunderstanding at this stage impacts the whole process.
How does a voice agent detect the end-of-turn boundary?
Inside the Voice AI system, human speech is not processed as one big file, rather in the form of chunks like 0–100ms, 100–200ms, 200–300ms, and so on. And what the system wants to know is when the user has indeed stopped speaking. That moment is the end-of-turn boundary
What are the different methods used for turn detection?
The different methods used for turn detection are:
- Audio-based detection
- Text-based detection
- Hybrid detection
What metrics are used to evaluate turn detection performance?
Metrics that are used to evaluate turn detection performance are:
- Mean shift time: It is the primary metric which is the duration between the silence ends and the detector detects that speech has ended.
- False Positive: It is a classic sequence labeling problem in which system wrongly labels the end of speech

