

Latency in AI Voice is the delay that comes when a caller speaks and the AI voice agent starts to respond.
In batch-processing or text-based AI, latency is a mild concern, However, for Voice AI, it is something that distinguishes good apps from great ones. This is because speech is a continuous, turn-based, and time-sensitive way of conversation and a small unnatural pause can disrupt the coordination between listening, thinking, and speaking. Therefore latency in AI Voice is not just a surface level performance issue but a core engineering problem.
The main goal of conversational AI apps is to provide natural human-like conversation that is different from monotonous, flat, robotic voices. To accomplish this, an application must converse without long silent gaps. Otherwise, the realism is shattered.
The voice AI apps consist of various components that capture audio, understand it, and generate AI responses. Latency does not originate from a single component; rather it is a cumulative result of all these interconnected systems and depends on their design, sequence and coordination. Optimizing only one stage of this interconnected system rarely produces valuable improvement therefore solving latency at a system level is important to overall efficiency.
Explore more about: Technical Foundations Behind High-Performance AI Calling Systems
What Latency in AI Voice?
Latency in AI Voice is defined as total time delay that comes when a person/callers speaks and when an AI response is produced.
Response generation consist of following steps:
- Audio signal capture
- Signal encoding & preprocessing
- Speech recognition (ASR)
- Intent / language understanding
- Response generation
- Speech synthesis (TTS)
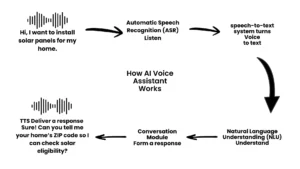
During each step a small amount of delay is added within the system. This individual delay is called component latency. Overall, latency is the cumulative result of all these interconnected systems. This overall latency is known as end-to-end latency. And from a technical point of view end-to-end latency is the main pain point that needs to be addressed to make the voice AI system natural and human-line.
As we know, in real life, the point of perfection cannot be achieved; so the question is: what’s the acceptable latency for voice AI agents?
Technically speaking, there is no universal benchmark for the acceptable latency but the goal is that it must be in a range that is unnoticeable to the human ear. For voice AI agents, usually latency under 1000ms is considered OK for smooth conversation. While 2000ms is considered an upper limit before responses start to feel disruptive.
But the overall formula is, responses must be in a limit that feels natural and arrives quickly enough to feel human but not so fast that they seem rushed and intrusive.
From a system perspective, these timing limits serve as strict TIME rules. In order to keep the whole conversation in sync, it’s important to complete the whole process within this time.
If the system takes longer than 2000-ms to complete this process; listening, thinking, and speaking phases no longer remain coordinated. In this case, even if the system answers correctly the timing is already off, so the response does not fit properly into the conversation. This makes latency a design-time constraint rather than a post-processing concern.
Understanding the End-to-End Voice AI Latency Pipeline
Each stage from audio receiving to response generation adds a small delay as component latency, and these delays accumulate as end-to-end latency. Understanding this full pipeline is essential for identifying where latency originates and how to eliminate or optimize it.
Audio Signal Capture
It is the first stage of a pipeline that continuously collects raw sound data from a microphone or audio stream. At this stage, buffering and framing choices introduce delay.
Signal Encoding and Preprocessing
At this stage, the sound waveform is converted into a digital form usually in binary 0,1 format that the system can analyze. Noise handling, normalization, and format conversion add some micro delays.
Automatic Speech Recognition (ASR)
Automatic Speech Recognition transcribes audio into text. This process often adds a significant latency because it’s one of the most computationally intensive steps.
Natural Language Processing
Once the speech is in text form, it is interpreted to determine meaning, intent, or conversational context. Delays at this stage depend on the complexity of interpretation and the amount of contextual information being processed.
Response Generation
The time it takes AI to generate its response based on the understood intent. More complex requests may require pulling info from databases or other systems, which can add extra delay.
Text-to-Speech (TTS)
The time it takes for the system to convert the generated text response back into an audio voice. As this step includes voice generation, prosody shaping, and audio formatting therefore it is also a computationally intensive process.
Network Latency
Network latency describes time it takes for data to travel between devices, servers, and cloud systems plus time to handle audio playback.
Primary Sources of Latency Inside Voice AI Systems
From the previous section, we come to know that latency originates in each step and builds up in output. The total amount of delay defines whether the conversation is unnatural, flat and robotic or human-like.
To solve the latency problems, it’s very important to accurately diagnose it first. Therefore, in this section we will discuss primary sources of latency based on where and why the delay occurs.
Audio Capture and Streaming Delays
Audio capture and streaming are the initial sources of latency. It occurs when audio enters the system and is processed for downstream steps. Here latency can occur due to three main reason:
- Buffer Sizing
- Chunking strategies
- blocking vs streaming capture
Buffer Sizing
A buffer is a temporary storage area where incoming audio is stored before processing begins. Buffer sizing refers to the decision about how much audio data is collected in this buffer before the system starts processing it.
In Voice AI systems, audio is buffered in small time-based segments, such as milliseconds of sound. The system starts the process only when enough data is collected to perform analysis and downstream processing
Larger buffers provide more audio context. Therefore, early audio analysis and speech recognition can operate more reliably. In contrast, smaller buffers provide less audio context, which can lead to incomplete analysis and increase the probability of recognition errors.
As larger buffers take longer to fill so the system needs to wait longer to initiate the process. On the other hand, smaller buffers fill more quickly and the system starts processing earlier and reduces latency but it requires more frequent processing .
Choosing the right buffer size depends on a balance between responsiveness and processing stability. Poor sizing can either introduce unnecessary waiting or cause the system to process too frequently that increases latency elsewhere in the system.
Chunking Strategies
Chunking strategy controls how buffered audio is split into pieces and processed. If the chunks are larger, the system has to wait more but processing will be more stable. Whereas if chunks are smaller, waiting time may reduce but it requires more frequent updates and synchronization. The chunk size directly controls how early recognition and understanding can start.
Blocking vs Streaming Capture
In blocking strategy, the system has to wait until enough audio is collected before moving to the next step. Whereas streaming uses very small, rolling buffers and audio is processed incrementally as it arrives. Blocking capture introduces unavoidable delay, while streaming capture allows downstream stages to begin work earlier and reduces accumulated latency.
Speech Recognition Latency
It is the time delay that appears when audio sound is converted into the text form. This process often adds a significant latency because it’s one of the most computationally intensive steps.
The delay may appear due to
- Type of recognition system: Batch Recognition or Streaming Recognition
- Acoustic model complexity
Batch Recognition
In batch recognition, speech to text conversion occurs in the form of batches which means that the system waits for a predefined size of audio or batch to be collected and then converts it into text. In case of batch recognition, full batch or audio segment is available, so the system has more information to work with. And the transcriptions that come out are final with more accurate words, pauses, and sounds.
However, this approach adds more waiting time that increases overall latency because downstream stages have to wait to start until recognition completes.
(Audio finishes) → (Recognition runs) → Final transcription
Streaming Recognition
In streaming recognition, the system processes the audio continuously without waiting for speech to complete. As soon as enough audio is received to make a prediction, the system produces recognition output.
In this type of recognition, text is made available promptly to the downstream stages like indent detect and response generation. So, they start without delay which reduces end-to-end latency.
Streaming systems generate partial transcriptions based on the audio heard so far. Partial transcriptions are not always stable and text may need correction, reorder, or replacement when the additional audio is received.
(Audio starts) → Partial text → Updated text → Final transcription
Acoustic Model Complexity
The complexity of the acoustic model contributes to the overall latency. These systems analyze the relationship between an audio signal and the phonemes or other linguistic units that make up speech to detect variations in tone, pronunciation, and timing. Although it improves recognition accuracy but adds delays.
Language and Intent Processing Latency
Language and Intent Processing Latency is the delay that appears when a Voice AI system understands the meaning of transcribed text, comprehends its intent and context.
Delay may appear due to
- Model Inference Time
- Prompt or Context Construction Overhead
- Context Window Management
Model Inference Time
Model inference time is the total time taken by the model to interpret and comprehend the transcription. Inference time increases when the system has to do complex reasoning or interpret difficult, longer and ambiguous phrases. Moreover, the more the length of transcribed text, the more time the system will take for interpretation.
Prompt or Context Construction Overhead
The transcribed text cannot be interpreted in vacuum; rather, the system needs context in form of previous dialogue turns, conversation state, or system instructions to comprehend it.
This step takes time because the system might have to gather related information from multiple sources like knowledge base, CRM, and other related information sources. Even if the inference time is less, context construction introduces significant additional delay.
Context Window Management
As conversations continue, the system carries forward more information from earlier turns. This growing body of context must be managed carefully.
Handling longer context windows requires extra processing to decide which parts of past conversation are still relevant, how they relate to the current input, and how they should be represented during inference. If the system simply keeps expanding the context without control, each new turn takes longer to process.
Over time, this can introduce increasing delay at every step of the conversation. Without careful design, the system slows down gradually, even if individual components have not changed.
Response Generation Delays
Response generation delays include additional time that comes in the process when creating the content of the reply and controlling when that reply should be delivered.
The delay may appear due to
- Incremental Response Generation
- Turn-Taking Logic
- Interruption Handling
Incremental Response Generation
Like previous stages of the AI voice generation process, response generation also occurs in incremental form piece by piece. So the speech begins to form even before the entire response is finalized.
The speed at which these pieces are generated is known as token generation speed. If the speed of token generation is slow, it takes more time to generate meaningful text necessary to generate speech. So, slow token generation speed prohibits response from beginning on time.
Turn-Taking Logic
Turn-taking logic determines when the system should speak. The engineers must decide whether the system should be conservative or aggressive in response.
Conservative system allows the speaker to complete talking and then replies. It avoids interruptions. Whereas an aggressive system responds quickly but there is risk of interruption and speaking over the user.
If the system is conservative, it waits longer to make sure that the speaker is done talking. It avoids interruptions but adds delay before responding. If it is aggressive and responds too quickly, it risks speaking over the user.
Finding the right balance between caution and speed is difficult and adds latency. The time spent making turn-taking decisions contributes directly to response delay, even before speech synthesis begins.
Interruption Handling
Conversations are dynamic. Sometimes the speaker starts talking again even when the system is still preparing or delivering a response.
In this situation, the system must act properly by taking following actions:
- Stop or pause the current response
- Re-evaluate the new input
- Decide whether to continue, restart, or change the response
Each of these decisions takes time. In order to handle interruptions, engineers have to introduce additional control overhead that increases overall latency.
Speech Synthesis Timing Issues
Speech Synthesis is the final step in which the system converts textual response into speech that is delivered as reply.
The delay might appear in following forms:
- TTS Initialization Delays
- Prosody Alignment Costs
- Audio Packetization and Playback Scheduling delay
TTS Initialization Delays
Before the system can produce any sound, the text-to-speech process must be initialized. This setup step happens even when the response content is ready.
In response generation text-to-speech is a critical step. Before it starts, another process called TTS Initialization must occur. During this process the system prepares voice parameters such as voice type, tone settings, and speech rate. It also loads the necessary internal state and configures audio output settings.
This initialization time adds a fixed delay at the start of every response. No matter how fast earlier processing stages are, the system cannot speak until this setup is finished.
Prosody Alignment Costs
Natural human-like speech synthesis requires the system to determine how the speech should sound, including pauses, emphasis, rhythm, and intonation. This process is known as prosody alignment.
Although it improves clarity and naturalness, it adds additional processing steps which increases latency.
Audio Packetization and Playback Scheduling
Once speech audio is generated, it is not played instantly as a single continuous sound. Instead, it is divided into smaller audio packets that can be sent to the playback system.
These packets must be scheduled correctly so that speech plays smoothly and without gaps. Timing decisions at this stage determine when the first sound is heard and how smoothly playback continues.
If packetization or scheduling is poorly coordinated, audio may be delayed even after synthesis is complete. This extends overall latency.
In this blog, we covered the key sources of latency in voice AI systems. If you want to explore practical techniques to reduce latency across the voice AI pipeline, you can read our detailed guide about: Reducing Latency in Voice AI Systems: Practical Optimization Techniques Across the Pipeline
FAQs about Root Causes of Latency in AI Voice Systems
1. What is latency in AI voice systems?
Latency in AI Voice is defined as total time delay that comes when a person/callers speaks and when an AI response is produced.
2. Why is latency more critical in AI voice than in text-based AI?
Latency is more critical in Voice AI because speech is a continuous, turn-based, and time-sensitive way of conversation and a small unnatural pause can disrupt the coordination between listening, thinking, and speaking. Therefore latency in AI Voice is not just a surface level performance issue but a core engineering problem.
3. What is considered acceptable latency for AI voice agents?
There is no universal benchmark for the acceptable latency but the goal is that it must be in a range that is unnoticeable to the human ear. For voice AI agents, usually latency under 1000ms is considered OK for smooth conversation. While 2000ms is considered an upper limit before responses start to feel disruptive.
4. Why doesn’t optimizing one component fix latency in AI voice systems?
The voice AI apps consist of various components that capture audio, understand it, and generate AI responses. Latency does not originate from a single component; rather it is a cumulative result of all these interconnected systems and depends on their design, sequence and coordination. Optimizing only one stage of this interconnected system rarely produces valuable improvement therefore solving latency at a system level is important to overall efficiency.
5. Why is latency a design-time constraint rather than a post-processing issue?
Latency is a design time or core engineering issue because it does not appear on its own. It depends on how the system is designed and how the process from voice capture to AI response generation flows through the system. For example if you have designed your system on the basis of blocking and batch strategies rather than streaming strategy and your system has a complex acoustic system for speech recognition then there will be more latency.

